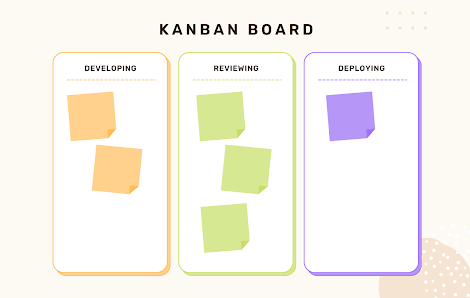
Work-in-progress limits are used to reduce the number of things that are actively being worked on by your team at once. The columns on our board that represent in progress are developing, reviewing, and deploying.
We could assign limits to the number of cards in each column, all in progress columns or per user. For our experiment, we chose to assign the WIP limit across all 3 columns. So for the first two days, we could only have 2 items across all columns.
After activating this rule lots of things changed very quickly...
Quality improvements
parts of our process that were not writing code increased in quality, we found that reviews had more people in them and were getting processed faster and with what felt like more detail in them.
Our process includes people reading and commenting on tickets before our elaboration sessions, in order to have a base understanding and shorter meetings. Sometimes it can be difficult to make sure this is being followed, this quickly improved and there were many insightful questions on the upcoming tickets as well as extra tickets not scheduled for elaboration.
Easier to understand what was happening
As lead engineer i found it much easier to know what was going on, on the team. We dont have stand up meetings but follow some simple rules for ticket updates: comment an update on the ticket when picking it up, showing your plan for the day.
- Comment an update each morning on tickets you own showing the plan to move it forward that day.
- Comment general updates on tickets so people know what is going on.
- Prefer talking on tickets over talking on slack, if you do talk on slack link in the ticket.
This mixed with having less things on the board meant it was really easy to know the current state of the team with a glance at our board. It also made it a lot clearer what the bottlenecks in our process were, before we would not notice that a deployment of stored procedures took a long time, but after the change it became very painful and we had to address the problem.
Increased collaboration
By having a limit that was less than the number of engineers on the team often people found themselves pairing on work more frequently in order to push tickets across the board. Collaboration is one of our teams values and our preferred way of working, the lower wip limits have really increased the amount of pairing going on!
Interesting points
we had to be careful to split tickets so that we avoid enforced waits, as a blocked ticket would count against our wip limit. For example we might have to wait for a 3rd party to respond before we can continue working on a ticket. To get around this we would split the ticket around the wait so we have two tickets, one to send out information and one to process received updates. Sometimes even with a wip limit of 2 we still only had 1 ticket in play, im not 100% on what caused this but one thought is that once an engineer picks up an idle task such as doing some learning if a space then became available they wouldnt notice for a while.
Conclusion
looking at our cycle time and ticket velocity from just after the experiment started, it appears that our cycle time was reduced, we saw an initial spike in velocity as we completed all the tickets in progress and then returned to a similar velocity as we had before.
This is quite interesting as based on initial data it seems that we didnt hugely increase the amount we deliver in a given period but we did reduce cycle time which would allow us to change direction faster if we need to process some incoming work quickly. As well as what appears to be a big increase in team focus and quality. So weve decided to adopt a wip limit into our team ways of working, the value we decided on for now is (engineers / 2) + 1.